На первой полосе | Авто (мир автомобилей) | Hi-Tech | Деньги. Инвестиции. Кредиты | Работа и карьера | Семья и дом | Спорт, туризм и отдых | Я ль на свете всех милее ? | Мужикам всех стран... | Недвижимость | Наука и образование | Исследования и обзоры | Странности и причуды | ТОПы (супер-рейтинг) | С юмором по жизни...
17.08.2006
Поиск по сайту - статичный контент (Perl)
Поиск по сайту, не самый сложный элемент, но довольно муторный. Так не хочется его делать, а надо. Я не буду рассматривать возможности внедрения в сайт поисковых форм Яндекса или Google, про это можно почитать у них самих. Будем делать собственный поиск по сайту.
Итак, что у нас дано:
-
сайт состоящий из статичных страниц;
-
файлы страниц расположены в разных папках различного уровня (у меня CMS собирает ЧПУ);
-
база данных MySQL (не использовать базу данных в поисковой машине - странное занятие, тем более что сейчас базы данных уже не роскошь);
Для того что бы у нас осуществлялся поиск нужно будет собрать "поисковые индексы". Я использую для этого два способа (способов, на самом деле, гораздо больше): простой и немного сложнее. В первом я использую встроенные функции MySQL базы данных, во втором - собственный велосипед.
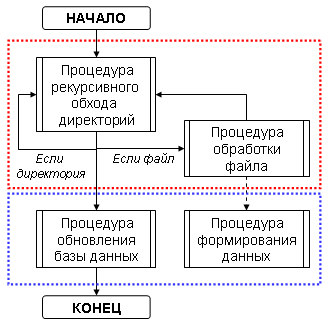
Определим алгоритм работы скрипта индексирования поисковой машины (основные подпрограммы):
Красным пунктиром выделены стандартные процедуры для обоих способов, процедуры выделенные синим радикально отличаются.
- Процедура рекурсивного обхода директорий - процедура, последовательно проходящая по файлам и папкам нашего сайта и выбирающая нужные файлы;
- Процедура обработки файла - процедура, обрабатывающая контент файла;
- Процедура формирования данных - обработанный контент собирается в блок данных для переноса в базу данных;
- Процедура обновления базы данных - сформированный блок данных заносится в базу данных;
Алгоритм работы скрипта вывода результатов поиска:
Данный скрипт нужно максимально упростить, так как индексацию мы запускаем максимум раз в сутки, то поисковый скрипт запускается на несколько порядков больше раз и тратить ресурсы во время поиска - нецелесообразно. Для этого требуется максимально оптимизировать информацию в базе данных, что бы она возвращала нам максимально подготовленную информацию для вывода, чтобы не производить лишних манипуляций.
Какая информация нужна нам для вывода результатов запроса:
-
URL страницы - ссылка на найденную страницу;
-
название страницы - эту информацию мы будем брать из тега страницы;
-
краткое описание страницы - эту информацию мы будем брать из мета-тега description страницы.
В качестве "подопытного кролика" я выбрал портал АльфаКМВ. Этот ресурс имеет в своем составе немногим более 3000 страниц разной вложенности в папках и можно спокойно оценить скорость работы нашей поисковой системы.
1. Способ первый: использование встроенных функций
Хоть MySQL считается не особо "навороченной" базой данных (хотя я лично так не считаю), у неё есть неоспоримые плюсы - это простота использования, а основной, в нашем случае, индекс FULLTEXT, который без особых сложностей организует нам прекрасный поиск. нужно просто приложить к этому небольшие усилия:
1.1. Организация таблицы
Индексная таблица состоит всего из четырех полей - ссылка на страницу (url), заголовок страницы (title), описание страницы (description) и текстовая часть (полнотекстовый индекс):
CREATE TABLE `search` (
`url` varchar(250) NOT NULL,
`title` text NOT NULL,
`description` text NOT NULL,
`search` text NOT NULL,
PRIMARY KEY (`url`),
FULLTEXT KEY `s` (`search`)
) TYPE=MyISAM;
1.2. Рекурсия
Вторым этапом нам нужно пройтись по всем папкам и файлам сайта для индексации, для чего воспользуемся рекурсией.
...
Рекурсия - вызов функции или процедуры из неё же самой (обычно с другими значениями входных параметров), непосредственно или через другие функции (например, функция А вызывает функцию B, а функция B — функцию A). Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
...
Следует избегать избыточной глубины рекурсии, так как это может вызвать переполнение стека.
...
Задумчиво, но так как мы не знаем глубину папок в которых могут лежать файлы сайта, то прийдется использовать её, хотя можно поискать на CPAN, но мне кажется, это лишняя трата времени, быстрее написать самому.
Создаем скрипт, который будет индексировать наш сайт, назовем его index.pl.
#!/usr/bin/perl
# Подключаем основные модули
use strict;
use warnings;
use DBI;
# "Локаль" - обязательно, т.к. кириллицу мы будем использовать и в регах
use locale;
use POSIX qw(locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, 'ru_RU.CP1251');
# Обозначаем глобальные переменные
use vars '$dbh', '$url_start', '$dir_start', '@dir_filter', '@file_type';
# Директория DocumentsRoot сайта
$dir_start = '/var/www/my_sites/html';
# Домен сайта
$url_start = 'http://www.my_sites.ru';
# Фильтр директорий (директории, которые исключаются из индексации)
@dir_filter = (
'cgi-bin',
'images',
'temp',
);
# Фильтр файлов (какие расширения файлов индексировать)
@file_type = (
'shtml',
'html',
'htm',
);
# Сразу отправляем заголовок браузеру
print "Content-type: text/html; charset=windows-1251\n\n";
# Открываем временный файл для хранения данных
open (TMP, '>>', '/var/www/my_sites/cgi-bin/search/search.txt');
flock (TMP, 2);
# Передаем управление процедуре рекурсии
&recursion();
# Закрываем временный файл
close TMP;
&update_db;
print 'Индексация завершена!';
exit;
sub recursion {
# Получаем текущую директорию рекурсии относительно DocumentsRoot
my $postfix = shift || undef;
# Формируем абсолютный путь текущей директории
my $dir = $dir_start.($postfix || '');
# Объявляем локальным переменные FOLDER (в основном нам нужен дескриптор*)
local *FOLDER;
# Открываем директорию
opendir (FOLDER, $dir);
# И последовательно считываем
while (my $item = readdir FOLDER) {
# "отсекаем" элементы '.' и '..' что бы не "выскочить" на директорию выше
next if $item eq '.' || $item eq '..';
# Определяем относительный путь
my $path = ($postfix || '').'/'.$item;
# Если элемент списка - директория, то порождаем процедуру вглубь рекурсии
&recursion($path) if -d $dir.'/'.$item && !map {$path =~ /^\/$_/} @dir_filter;
# Если элемент списка - файл, то передаем относительный путь к нему в процедуру обработки
&file_parse($path) if -f $dir.'/'.$item && map {$path =~ /\.$_$/} @file_type;
}
# Закрываем директорию
close FOLDER;
# ... и возвращаемся
return 1;
}
Как видно - никаких сложностей. Однако хочу заметить, что в глубь рекурсии мы уходим только для директорий, а не символьных ссылок, причем, я бы и не рекомендовал использовать символьные ссылки, чтобы рекурсия не зациклилась во время обработки.
1.3. Предварительное формирование данных или просто формирование данных
Третий этап - подготовка файла и индексации. Так как очень часто на страницах сайта используются SSI внедрения, то их нужно будет включить в основное тело страницы.
...
в одном разделе сайта дизайнер внедрил красивый заголовок через SSI, когда поисковая система проиндексировала страницы, то ключевые слова заголовка были пропущены, и поиск осуществлялся "криво"
...
sub file_parse {
# Получаем относительный путь к файлу
my $file = shift;
# Открываем файл страницы
open (FILE, "$dir_start$file");
# Объявляем переменную в которой бодем собирать контент
my $content;
# Построчно производим обработку
while () {
$_ =~s / /&_include_ssi($file ,$1)/eg;
if ($content) {$content .= $_} else {$content = $_}
}
# Закрываем файл страницы
close FILE;
# Обработка контента
# Убираем "жесткие" пробелы и пробельные символы
$content =~s /\ / /gi;
$content =~s /[\s\t\r\n]/ /gi;
# Выбираем заголовок и описание страницы
my ($title) = $content =~ /<\\title>/i;
my ($description) = $content =~ //i;
# Производим "чиску" контента оставляя только символы
$content =~s /[^\w\-\s]/ /g;
$content =~s /\s{2,}/ /g;
# Отправляем обработанный контент, путь, заголовок и описание в процедуру обновления БД
&update_data(\$content, $title, $description, $file);
return 1;
}
sub _include_ssi {
# Получаем имя HTML файла и имя файла SSI
my ($file, $ssi) = @_;
# Объявляем переменную - путь к файлу внедряемому через SSI
my $path;
# Если файл берется из корня
if ($ssi =~ /^[\\\/]{2}/) {
$path = $dir_start.$ssi;
# "Чистим" двойные "слеши"
$path =~s /([\\\/]){2,}/$1/g;
# Иначе
} else {
# Определяем директорию основного файла
my ($path) = $file =~ /(.*)[\/\\].*?/;
if ($path) {$path .= $ssi} else {$path = $ssi}
# "Чистим" двойные "слеши"
$path =~s /([\\\/]){2,}/$1/g;
}
# считываем контент файла
open (SSI, $path);
my $content = join('', );
close SSI;
# Возвращаем контент файла
return $content
}
В данной процедуре, производится обработка контента файла. Хочу заметить, что SSI я обрабатываю только для директивы include virtual, при этом не проверяю внедряемый файл, если же через include virtual внедряются скрипты или используются дополнительные директивы, то данный код нужно будет соответственно доработать. Так же может возникнуть вопрос, почему я разбиваю скрипт на такие маленькие процедуры, когда, по большому счету, достаточно было бы описать это в одной процедуре - все это только лишь для того что бы облегчить понимание предмета, а последнее вынесение процедуры update_data - потому что дальше способы индексации разнятся между собой.
1.4. Обновление блока данных
В общем, в эту процедуру мы передаем уже практически готовые данные для вставки в базу данных, поэтому:
Для варианта с LOAD DATA:
sub update_data {
# Получаем данные
my ($content, $title, $description, $file) = @_;
# Формируем строку
my $line = $url_start.$file."\t".$title."\t".$description."\t".$$content."\n";
# Записываем строку во временный файл
print TMP $line;
return 1;
}
для варианта с INSERT INTO:
sub update_data {
# Получаем данные
my ($content, $title, $description, $file) = @_;
# Формируем запрос
my $update = "INSERT INTO alwm5_search_one
SET
url = '$url_start$file',
title = '$title',
description = '$description',
search = '$$content'
";
# Выполняем запрос к БД
$dbh->do($update);
return 1;
}
Правда, во втором варианте нужно не забыть предварительно подключится к базе данных.
1.5. Обновление базы данных
Можно рассмотреть два варианта обновления данных:
Если мы обновлять данные будем с помощью LOAD DATA. Информация уже сформирована и требуется только обновить базу данных:
sub update_db {
# Подключаемся к базе данных
$dbh = 'DBI'->connect('DBI:mysql:database=search;host=localhost;port=3306', 'user', 'password')
or die $DBI::errstr;
# Обнуляем таблицу
$dbh->do('DELETE FROM search;')
or die $DBI::errstr;
# Загружаем данные
$dbh->do('LOAD DATA INFILE "/var/www/my_sites/cgi-bin/search/search.txt" INTO TABLE search;')
or print "ERROR!!! $DBI::errstr
\n";
# Отключаемся от базы данных
$dbh->disconnect();
# Удаляем временный файл
unlink '/var/www/my_sites/cgi-bin/search/search.txt';
1;
}
|
Ключевые слова: |
интернет программирование |
|
Автор: |
Томулевич Сергей (Phoinix) |
|
Источник: |
www.asit.ru |
Возврат к списку
| 


